
第2节,使用pandas的isna方法检查excel是否存在空值
对于excel里的数据,我们有时需要做一些数值方面的检查,如果内容不符合要求,那么需要追根溯源找到问题所在。
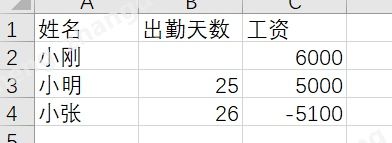
1. 检查单元格的空值
对于这类偏向于分析的操作,pandas最适合不过了
import pandas as pd
file_path = "./data/工资.xlsx"
df = pd.read_excel(file_path)
print(df['出勤天数'].isnull)
输出结果
<bound method Series.isnull of 0 NaN
1 25.0
2 26.0
Name: 出勤天数, dtype: float64>
可以看到是有空值存在的,想要获取所所有的空值,可以对df进行一次过滤
cq_null_df = df[pd.isna(df['出勤天数'])]
print(cq_null_df)
输出结果
姓名 出勤天数 工资
0 小刚 NaN 6000
2. 检查数值范围
工资不可能小于0, excel在编辑时可能出错导致输入负数,使用pandas可以很轻松的找出这些异常数据
err_df = df[df['工资'] < 0]
print(err_df)
程序输出结果
姓名 出勤天数 工资
2 小张 26.0 -5100

扫描关注, 与我技术互动
QQ交流群: 211426309
