
第8节,openpyxl 计算两列数据相加的和
1. 数据说明
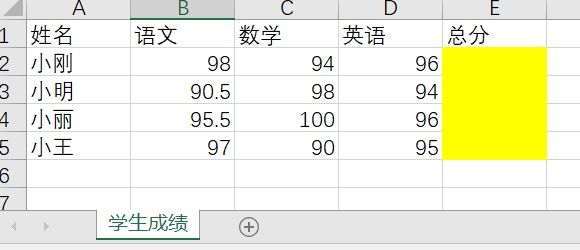
数据地址:./basic/data/求一行数据的和.xlsx
2. 思路分析
思路1,按行读取,每一行数据,读入到一个列表中,例如小刚这一行
lst = ['小刚', 98, 94, 96, '']
然后对列表进行切片操作,切片后所得到的列表,只包含分数
lst = [98, 94, 96]
对列表进行求和。
思路2,按列来读取数据,B列,C列,D列分别读入到一个列表中
lst_b = ['语文', 98, 90.5, 95.5, 97]
lst_c = ['数学', 94, 98, 100, 90]
lst_d = ['英语', 96, 94, 96, 95]
对这三个列表进行切片操作,所得到的列表只包含分数
lst_b = [ 98, 90.5, 95.5, 97]
lst_c = [ 94, 98, 100, 90]
lst_d = [ 96, 94, 96, 95]
创建一个新的列表,lst_sum , lst_sum[0] = lst_b[0] + lst_c[0] + lst_d[0]
依次类推。
两个思路都可行,我选择实现第二个,原因在于这算计算方法更具有代表性,假如要求你计算语文和英语两科的总和,那么第二种计算方法不需要进行修改,而第一种计算方法就需要修改才能满足要求。
3. 代码实现
from openpyxl import load_workbook
file_path = './basic/data/求一行数据的和.xlsx'
workbook = load_workbook(file_path)
sheet = workbook.get_sheet_by_name('学生成绩')
def sum_column(columns, start_index, end_index):
"""
计算columns 列的和
:param columns: 列表,多个列的名称
:param start_index: 有效数据开始的索引
:param end_index: 有效数据结束的索引
:return:
"""
value_lst = []
for column in columns:
values = get_values(sheet[column], start_index, end_index)
value_lst.append(values)
result = []
for value_tup in zip(*value_lst):
result.append(sum(value_tup))
return result
def write_column(column_values, column_index, start_index):
for index, value in enumerate(column_values):
sheet.cell(row=start_index+index, column=column_index).value = value
def get_values(column_or_row, start_index, end_index):
"""
获取一列,或者一行的所有数据,根据start_index 和 end_index 来确定切片范围
:param column_or_row: 列,或者行对象
:param start_index: 开始的索引
:param end_index: 结束的索引
:return:
"""
start_index -= 1
lst = []
for index in range(start_index, end_index):
lst.append(column_or_row[index].value)
return lst
result = sum_column(['B', 'C', 'D'], 2, sheet.max_column)
write_column(result, 5, 2)
workbook.save(file_path)

扫描关注, 与我技术互动
QQ交流群: 211426309
