
mpire--比multiprocess 更快的多进程库
mpire
mpire 是一个比Multiprocessing更快更容易上手使用的python多进程库。相比于原生的Multiprocessing库,mpire提供了非常有帮助的辅助功能,这些功能使用Multiprocessing同样可以实现,但肯定要耗费一些精力,因此不如直接拿来主义。
下图是mpire与Multiprocessing的性能对比
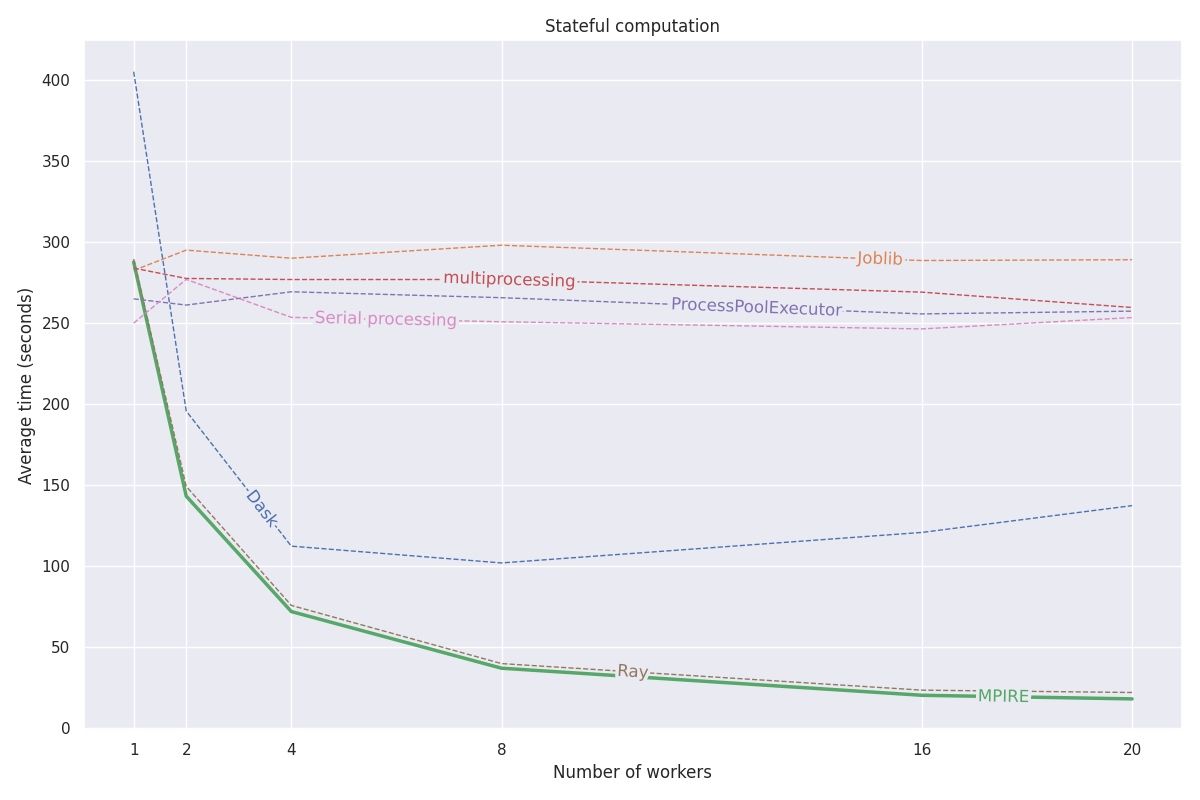
mpire在性能方面更有优势,但我更关注它所提供的辅助功能。
如何启动一个进程池
mpire启动进程池的方法与Multiprocessing没有什么不同,如果你已经熟练掌握Multiprocessing,mpire的学习成本并不高。
from mpire import WorkerPool
def dosomething(x):
return x + 1
with WorkerPool(n_jobs=4) as pool:
results = poll.map(dosomething, range(10))
进程池里有4个worker,一同处理10个任务。你可以控制子进程的启动方法,使用fork或者spwan, mpire所支持的启动方式和各平台对这些启动方式的支持情况如下图所示
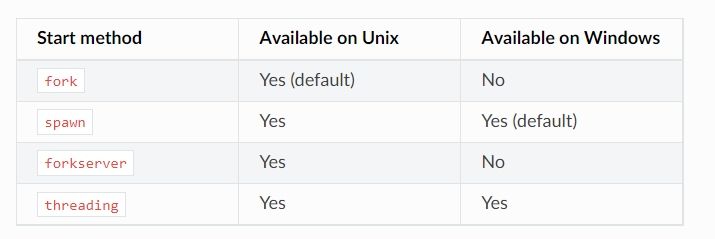
通过start_method可以设置子进程启动方式,fork是默认的方式,spawn会启动新的python解释器。
with WorkerPool(n_jobs=2, start_method='spawn') as pool:
绑定CPU
使用 cpu_ids参数可以让子进程绑定到指定的CPU上运行,这样做能在一定程度上提高进程的运行效率,效果不敢做太多承诺,因为绑定CPU只是明确的提出了要求,而即便你不提这个要求,现在的操作系统倾向于让一个进程尽可能在一个固定的CPU上运行。
worker state
mpire并没有使用什么特别的技术,但其提供的辅助功能的确可以让你在编写多进程的程序时更加顺手,程序结构更加合理。如果你希望每一个子进程有自己的状态,可以通过设置use_worker_state参数让每一个子进程可以管理自己的状态。配合上worker_init,让程序的层次更加分明。
import numpy as np
import pickle
def load_big_model(worker_state):
# Load a model which takes up a lot of memory
with open('./a_really_big_model.p3', 'rb') as f:
worker_state['model'] = pickle.load(f)
def model_predict(worker_state, x):
# Predict
return worker_state['model'].predict(x)
with WorkerPool(n_jobs=4, use_worker_state=True) as pool:
# Let the model predict
data = np.array([[...]])
results = pool.map(model_predict, data, worker_init=load_big_model)
在官网的这个例子里,每个子进程都需要加载一个模型文件,mpire允许你通过设置worker_init参数来指定加载模型文件的函数,加载好的模型保存在worker_state中,在model_predict函数中,则能通过worker_state获取加载好的模型。
这样做的好处是将模型预测和模型加载的过程解耦,model_predict函数不必关系加载的模型是什么,它只管做预测。如果不这样处理,使用multiprocess库,在不做额外的设计前提下,你只能选择在model_predict里进行模型的加载,这意味着函数每调用一次就必须加载一次。

扫描关注, 与我技术互动
QQ交流群: 211426309
